给博客搭建搜索系统
探索如何利用 Tantivy 库为博客构建高效的全文搜索系统。顺带介绍一些信息检索与 NLP 的知识。
核心思路
搜索系统是一个比较复杂的东西,大概分为以下几点:
- 分词:包括中文分词与英文分词
- 倒排索引:建立 token -> posting list 的映射
- 模糊匹配:包括编辑距离,n-gram 相似度
- 查询解析与组合:将用户查询拆分为 tokens,再使用布尔查询、加权查询、短语查询等,组合后进行查询
- 生成摘要,其中高亮显示关键词
分词
英文分词
英文分词相对简单,基本上分为3步
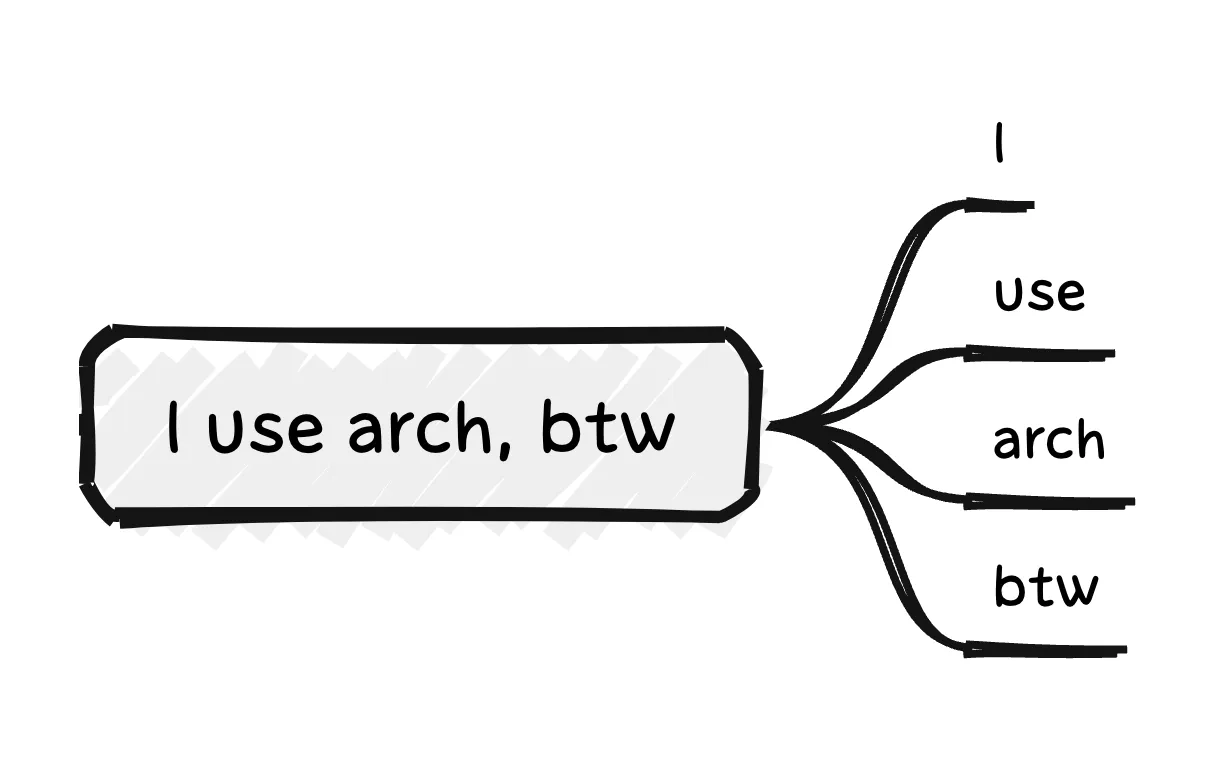
按空格分割,并去除标点符号 (Punctuation)
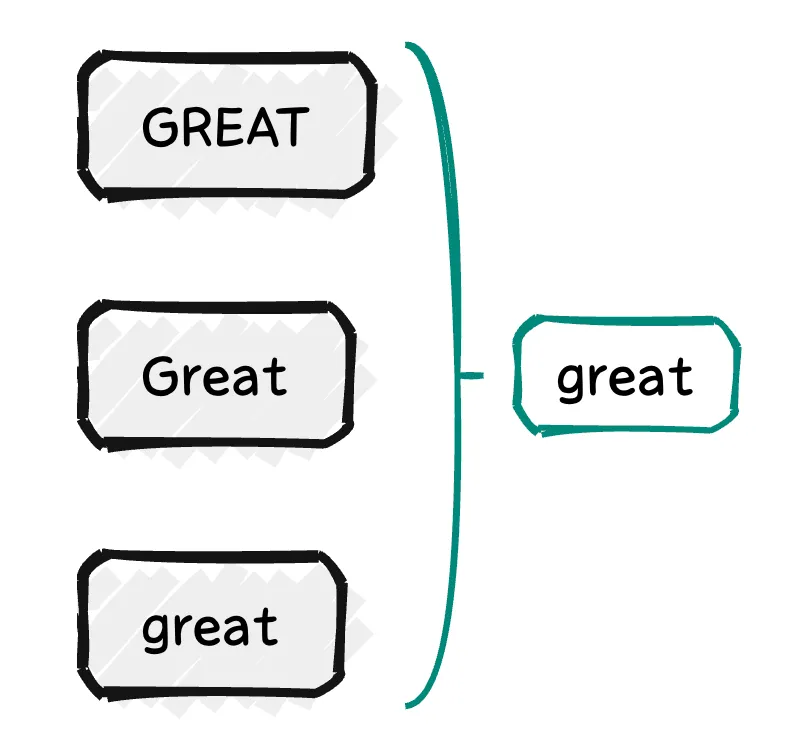
小写化 (Lowercasing)
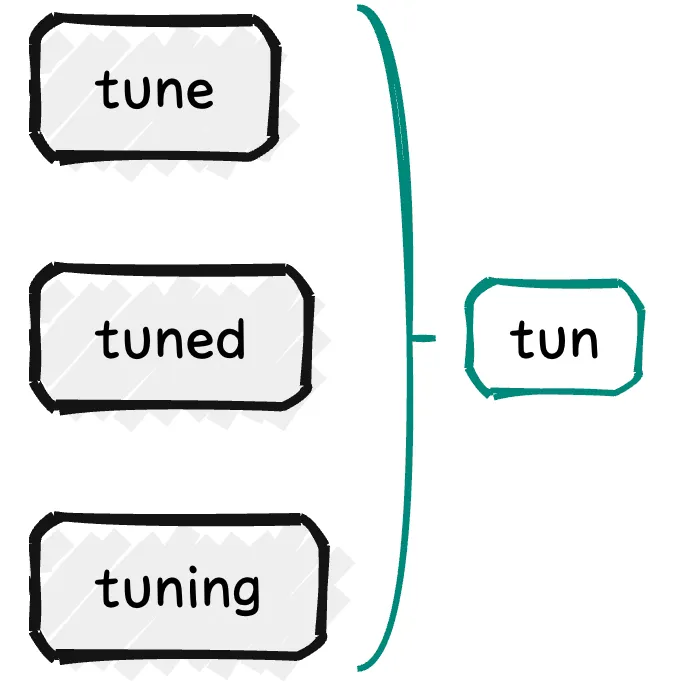
词根化 (Stemming)
英文里同一个词可能有进行时、过去式等,需要统一成它们的词根
中文分词
中文分词就复杂多了,但是好在有现成的库可以用,我选择了 jieba-rs ,它是 jieba 中文分词的 Rust 实现。可以很好地把一句话切分成 tokens,如:
fn main() {
// ANCHOR
let jieba = jieba_rs::Jieba::new();
let sentence = "我们中出了一个叛徒";
let words = jieba.cut(sentence, false);
assert_eq!(words, ["我们", "中", "出", "了", "一个", "叛徒"])
// ANCHOR_END
}
如果中文里面夹杂英文,jieba 会顺便把英文按空格和标点符号分割输出:
fn main() {
// ANCHOR
let jieba = jieba_rs::Jieba::new();
let sentence = "btw, 我用的是Arch Linux系统";
let words = jieba.cut(sentence, false);
assert_eq!(
words,
[
"btw", ",", " ", "我", "用", "的", "是", "Arch", " ", "Linux", "系统"
]
)
// ANCHOR_END
}
这样我们就无需使用两个 tokenizer 了,对中英文分别使用 tokenizer,再分别搜索的话,效果确实很好,但是后面生成摘要和高亮的时候就麻烦了,中英文 tokenizer 生成的摘要内容和高亮位置会有差异,很难合并,而且处理中英混合的搜索词时也很复杂。毕竟我的博客文章以中文为主,对英文搜索没什么需求,在这方面浅尝辄止,最后还是选择统一使用 jieba 分词。
停用词 (Stop Words)
在中英文中,有些字词使用极其广泛,却没什么实际含义(如“的”"the"),或者有实际含义,但是因为使用过于广泛,在大量的搜索结果中出现,使这些结果的评分都很高,无法帮助缩小搜索范围,这类字词被称为停用词。为了提高搜索的准确性和效率,一般会把这些词从 tokens 中移除。
tantivy 使用的英文停用词,和 Lucene 是一样的,来自这里 ,大部分都是虚词。
const STOP_WORDS: &str = [
"a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it",
"no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these",
"they", "this", "to", "was", "will", "with",
];
而中文停用词,我在网上找了一番,最后决定用的是这个
实现
得益于 tantivy 这一强大框架,实现起来相当简单
此处的代码仅供参考,实际使用的源码都在 my_blog 项目里的 search_utils 模块下。
fn cut() {
let mut jieba_analyzer =
// 这里的 `JiebaMode::CutAll` 是我给 tantivy 写的 jieba wrapper 里面加的,
// 内部就是调用 jieba 的 cutall 模式,也就是列出所有可能的分词,这样我们的索引会更丰富
TextAnalyzer::builder(jieba::JiebaTokenizer::with_mode(jieba::JiebaMode::CutAll))
// 分词后,移除过长的token
.filter(RemoveLongFilter::limit(40))
// 词根化
.filter(Stemmer::new(tantivy::tokenizer::Language::English))
// 英语停用词
.filter(StopWordFilter::new(tantivy::tokenizer::Language::English).unwrap())
// 小写化
.filter(LowerCaser)
.build();
let mut token_stream = jieba_analyzer.token_stream(query_text);
let mut tokens = Vec::new();
while let Some(token) = token_stream.next() {
// 去除空格token
if !token.text.trim().is_empty()
// 只保留中英文字符
&& is_cjk_or_en(&token.text)
// 移除中文停用词
&& !is_stop_word(&token.text)
{
tokens.push(token.text.to_string());
}
}
}
倒排索引 (Inverted index)
既然已经分好了词,那就可以开始建立索引了。
倒排索引的本质就是一个文本-->文本位置的映射,和前向索引 (forward index) 相反。
前向索引一般是这样:
| Document | Tokens |
|---|---|
| 1 | arch, linux, is, open, source |
| 2 | it, is, arch, linux |
| 3 | what, is, it |
而倒排索引则是反过来,并且会按 token 分割
| Tokens | Document |
|---|---|
| arch | 1, 2 |
| linux | 1, 2 |
| is | 1, 2, 3 |
| open | 1 |
| source | 1 |
| it | 2, 3 |
| what | 3 |
之后假如用户输入了 arch linux,那么我们可以按照取交集的方式,得出包含关键字的文档是 1 和 2
当然,具体实现更加复杂,不仅要记录 token 在哪个文档,还要记录具体的位置,并进行速度与存储占用的优化等等。
文本预处理
我的博客文章都是用 markdown 格式写的,对于分词来说,符号没什么影响,但是生成摘要的时候就会出现一堆 “##” 和 “**”,看起来十分难受。所以这个阶段主要是为了搜索后结果的可读性服务,并不会明显影响搜索的效果。
首先,使用 comrak 这个 crate 生成语法树,然后遍历它,并输出纯文本。
/// Recursively walk the AST and collect only plain text.
fn render_plain<'a>(node: &'a AstNode<'a>, output: &mut String) {
for child in node.children() {
match &child.data.borrow().value {
NodeValue::Text(t) => output.push_str(t),
NodeValue::Code(t) => output.push_str(&t.literal),
NodeValue::LineBreak | NodeValue::SoftBreak => output.push('\n'),
NodeValue::Paragraph
| NodeValue::Heading(_)
| NodeValue::Item(_)
| NodeValue::BlockQuote
| NodeValue::List(_)
| NodeValue::Table(_)
| NodeValue::TableRow(_)
| NodeValue::TableCell
| NodeValue::FootnoteDefinition(_) => {
render_plain(child, output);
output.push('\n');
}
NodeValue::CodeBlock(block) => {
output.push_str(&block.literal);
output.push('\n');
}
NodeValue::Link(_)
| NodeValue::Image(_)
| NodeValue::Emph
| NodeValue::Strong
| NodeValue::Strikethrough
| NodeValue::Superscript
| NodeValue::Subscript => {
// Just render the children, ignore formatting/URLs
render_plain(child, output);
}
_ => render_plain(child, output),
}
}
}
在这之后,输出的文本还不是特别美观,所以再用三个正则表达式处理一下。
use regex::Regex;
use std::sync::LazyLock;
// ANCHOR
pub fn preprocess_text(text: &str) -> String {
// 这里的 \p{Han} 是指匹配所有汉字,包括简中,繁中,日韩文中的汉字
static RE1: LazyLock<Regex> = LazyLock::new(|| Regex::new(r"([a-zA-Z])(\p{Han})").unwrap());
static RE2: LazyLock<Regex> = LazyLock::new(|| Regex::new(r"(\p{Han})([a-zA-Z])").unwrap());
static RE3: LazyLock<Regex> = LazyLock::new(|| Regex::new(r"\s+").unwrap());
// 把所有挨在一起的英文和汉字分开,比如“rust语言” -> “rust 语言”
let iter1 = RE1.replace_all(text, "$1 $2");
// 把所有挨在一起的汉字和英文分开,比如“使用regex” -> “使用 regex”
let iter2 = RE2.replace_all(&iter1, "$1 $2");
// 把所有连续的空白(包括空格、换行符等)合并为一个空格
RE3.replace_all(&iter2, " ").to_string()
}
// ANCHOR_END
处理过后的文本大致长这样

建立索引
我在此省略掉了一些和构建索引无关的代码,因此这段代码仅供示意流程,实际上无法直接运行。
这里我们将内容存储到了不同的 field 里,这是为了后续搜索时更方便。比如文章内容和标题是分开存储的,这样查询的时候,可以区分匹配标题和内容,若关键词匹配标题则可以获得更高的评分。文件的实际路径也存储到单独的位置,它和搜索的内容无关。文章的 tags 则存储到 facet 里面,之后可以根据 facet 来匹配,如果查询已经选定了某些 tags,那么不含这些 tags 的文章可以直接被过滤掉。
pub fn build_index() -> Result<(), CatError> {
let mut schema_builder = Schema::builder();
// prepare indexing options per-field with tokenizer name
let zh_indexing = TextFieldIndexing::default()
.set_tokenizer("jieba")
.set_index_option(IndexRecordOption::WithFreqsAndPositions);
let text_options_zh = TextOptions::default()
.set_indexing_options(zh_indexing)
.set_stored();
let content_zh = schema_builder.add_text_field("content_zh", text_options_zh.clone());
let title_field = schema_builder.add_text_field("title", text_options_zh);
let tag_facet = schema_builder.add_facet_field("tags", FacetOptions::default());
let path_field = schema_builder.add_text_field("path", STORED);
let schema = schema_builder.build();
let index = Index::create_in_dir(index_path, schema.clone())?;
// Register jieba tokenizer for Chinese
index.tokenizers().register("jieba", JIEBA_ANALYZER.clone());
let mut writer = index.writer(50_000_000)?;
for content in contents {
let mut doc = TantivyDocument::default();
for tag in tags.iter() {
let facet = Facet::from(&format!("/{}", tag.to_lowercase()));
doc.add_facet(tag_facet, facet);
}
// 在不同的位置存储不同的文本
doc.add_text(content_zh, &text);
doc.add_text(title_field, &title);
doc.add_text(path_field, &file_name);
writer.add_document(doc)?;
}
writer.commit()?;
Ok(())
}
模糊匹配
我们简单介绍一下模糊匹配,它有助于提高搜索结果的召回率,也就是能搜到的东西更多,但是会降低搜索的精度,也就是更容易搜到不相关的东西。
编辑距离
什么是编辑距离?顾名思义,就是将一个词更改为另一个词,所需要的最少编辑操作次数。编辑距离是一个泛化的概念,在搜索中一般用的是 Levenshtein distance。Levenshtein distance 允许的编辑操作包括:
| 操作 | 示例 |
|---|---|
| 将一个字符替换为另一个字符 | deah -> dear |
| 插入一个字符 | grat -> great |
| 删除一个字符 | suggesstion -> suggestion |
每进行一次上述的任意操作,编辑距离+1
当然,也有一些其他的编辑距离定义,比如,允许交换字符 (dera -> dear),或者,给不同的操作进行加权,比如替换操作,实际上是先删除,后插入,所以编辑距离为2,而交换操作,实际上是两次删除+插入,所以编辑距离为4.
n-gram
n-gram 是指文本中连续出现的 n 个单元(可以是字、词或字母)组成的序列。这里的 "n" 代表片段的长度。
比如当 n = 2 时,称之为 bigram,"Apple" 会被切成 "Ap""pp""pl""le",而 "Aple" 会被切成 "Ap""pl""le",这两个词的 bigram 非常相似,所以即使用户输入 "Aple",依旧能查询到 "Apple" 相关的信息。
n-gram 算法中,切分的 token 是有大量重合部分的,所以 n 越大,空间占用就会越大,计算速度也会更慢,但是保留的信息更多,匹配更精准。n 比较小的话,计算速度会很快,但是保留的信息很少,比如 n = 1 时,很容易匹配到大量无关信息。
实际上...
模糊匹配是我在搭建搜索系统的过程中尝试过的技术,但是发现不太符合需求。比如,将允许的编辑距离设为 1,看起来好像很小,但当关键词很短的时候,会匹配到大量不相关的结果,比如,"git" -> "get", "rust" -> "rush", "apple" -> "apply".
而 n-gram 也是类似,不相关结果太多,我希望我的搜索引擎还是能尽量准确些,所以没有用这些模糊匹配的技术。
查询解析与组合
处理用户输入
比如用户输入了:“Linux下Qt程序如何打包”,我们要如何处理呢?
非常简单,和刚刚分词那块的实现几乎一样,使用 jieba 处理输入,但这一次我们选择 search 模式,也就是为搜索专门优化的模式,很少重复分词,再过滤一下输出的 tokens 就行了。处理结果是这样:["linux", "qt", "程序", "打包"]
看起来很不错,jieba 顺利地把输入切分成了 tokens,我们又过滤掉了停用词。
假如 search 模式分词没分好怎么办?
我们来考虑一些极端情况:“乒乓球拍卖完了”,search 模式会分成:["乒乓", "乒乓球", "拍卖", "完"],而一般的理解,应该是["乒乓球拍", "卖完"]
可见 search 模式也不是万能的,此时如果用 cutall 模式,可以得到:["乒", "乒乓", "乒乓球", "乒乓球拍", "乓", "球", "球拍", "拍", "拍卖", "卖", "卖完", "完"],这样一来,我们就能得到“乒乓球拍”“卖完”这两个词了。
但是这样也有明显的问题,cutall 模式切出来太多单字了,而在现代汉语中,很少单独使用一个字,一般都是组成词语使用,所以单字大部分时候都是噪声,如果我们直接用 cutall 模式输出的 tokens 去搜索,那就会得到很多不相关的结果,比如包含“球”字和“完”字,“篮球赛完美结束”,和乒乓球拍和卖东西半点关系没有,但是直接被包含进来了。
所以我采取了组合并排除单字的方式,用 cutall 切一次,过滤掉所有单字,再用 search 模式切一次,再把两次的结果用集合去重。这样我们得到的结果就是:{"卖完", "乒乓", "乒乓球拍", "乒乓球", "拍卖", "完", "球拍"},相关性就高多了。
查询算法
Tantivy 是如何决定哪些结果可以显示,哪些结果要排在前面的?它使用打分制,评分越高的结果排名越靠前,没有任何得分的结果就不会显示。
Tantivy 使用的核心打分算法是 BM25,它具有以下特点:
- TF (Term Frequency):即词频,一个词出现次数越多,分数就越高
- IDF (Inverse Document Frequency):DF 是指有多少文档包含这个词,显然 DF 越高,这个词就越常见,IDF 可以简单理解为 DF 的倒数,基本上是 DF 越小,IDF 就越大,越意味着这个词更罕见。一般来说,我们认为越罕见的词提供的信息量越高,越有助于筛选文档。所以 IDF 越大,文档的评分就会越高。
- 词频饱和:TF 分数的增长会趋于平缓,当关键词出现的次数很多时,比如在 1000 字的文章中,出现了 20 次或 30 次,此时对分数的贡献差别不大。
- 文档长度归一化:BM25 会将文章长度也纳入考虑,长文章不会因为包含的关键词数量更多而占优势
构造查询
基础查询
之前也提到过,我的文章以中文为主,英文出现得比较少,所以接下来构造查询时,我们也要给它们加上不同的权重。
fn basic_query() {
for tk in tokens.iter() {
// jieba 已经把中英文分到不同的 token 里去了,所以只要这个 token 包含任何
// 汉字,就当作中文来处理
if contains_han(tk) {
// Chinese token: use exact TermQuery and boost against content
let term = tantivy::Term::from_field_text(content, tk);
let term_title = tantivy::Term::from_field_text(title_field, tk);
// 给在文章内容里出现的 token 赋予 1.5 的权重
let query = BoostQuery::new(
Box::new(TermQuery::new(
term,
IndexRecordOption::WithFreqsAndPositions,
)),
1.5,
);
// 在标题里出现的权重为 2
let title_query = BoostQuery::new(
Box::new(TermQuery::new(
term_title,
IndexRecordOption::WithFreqsAndPositions,
)),
2.0,
);
// should 表示出现能够增加评分,是“或”的关系,如果一篇文档一个 should 或 must
// 都没有出现,则得分为 0
clauses.push((Occur::Should, Box::new(query)));
clauses.push((Occur::Should, Box::new(title_query)));
} else {
// short token
let term = tantivy::Term::from_field_text(content, tk);
// 出现在文章内容里的英文权重为 1,也就是没有权重
let term_title = tantivy::Term::from_field_text(title_field, tk);
// 出现在标题里的英文权重为 2
let title_query = BoostQuery::new(
Box::new(TermQuery::new(
term_title,
IndexRecordOption::WithFreqsAndPositions,
)),
2.0,
);
let q1 = TermQuery::new(term, IndexRecordOption::WithFreqsAndPositions);
// must 表示必须出现,出现可以增加得分,如果没有出现,则这篇文档得分为 0,是“与”的关系
// 在这里用来提高搜索的精度,就是考虑到我文章里的英文本来就不多,而且多为专业术语,如果
// 搜索关键词里有英文,那文档里就必须出现,这样可以保证当搜索英文专业术语时,搜索结果里
// 的无关内容很少
clauses.push((Occur::Must, Box::new(q1)));
clauses.push((Occur::Should, Box::new(title_query)));
}
}
}
优化
目前我们的查询基本做到了,输入关键词,如果有内容就一定会被查到,如果只匹配了部分关键词,也能查到。但是还有个小问题,就是只要包含了我们输入的关键词,比方说输入了 3 个关键词,3 篇文章都包含了,虽然有的可能是在同一句话中,有的可能分散得很开,但得分都差不多,并没有让最相关的文章排在最前面。
举个例子,搜索“人工智能”的时候,一篇文章是讲人工智能的,另一篇是说:“智能冰箱是我们耗费了大量人工做出来的产品”,显然第一篇更符合,应该排在前面,但实际上并不一定。
因此,我们可以使用短语查询 (Phrase Query) 来优化,也就是不仅要求有这些词出现,还要求词之间挨得很近,并且顺序和输入的关键词完全一样,可以通过 slop 来调整允许的距离,比如设置为 10,举个简单的例子
| tokens | document | 出现位置 |
|---|---|---|
| 人工 | 1 | [0] |
| 智能 | 1 | [25] |
| 人工 | 2 | [7] |
| 智能 | 2 | [8] |
那么按照先前的查询逻辑,文档 1 和 2 都能成功匹配,但是按照短语查询的逻辑,文档 2 的“人工”和“智能”靠得很近,slop 为 1,小于 10,成功匹配,在短语查询获得了分数;而文档 1 的“人工”和“智能”的 slop 为 25,大于 10,无法匹配,在短语查询这块不得分。
先使用 jieba 的 search 模式切出来 tokens,再在 tokens 数量大于 1 时,加上额外的 PhraseQuery
fn phrase_query() {
if proximity_subs.len() > 1 {
let mut proximity_query = tantivy::query::PhraseQuery::new(proximity_subs);
// 设置适当的 slop
proximity_query.set_slop(10);
// 给匹配的文档设置高权重
let proximity_query = BoostQuery::new(Box::new(proximity_query), 5.0);
boolean_query = BooleanQuery::from(vec![
// 这里的 `boolean_query` 是我们之前的查询,所以设置成 must,必须要匹配
(Occur::Must, Box::new(boolean_query) as Box<dyn Query>),
// 短语查询是加分项,如果没有匹配,就失去了额外分数,但不会抛弃这个文档
(Occur::Should, Box::new(proximity_query)),
]);
}
}
过滤 tags
如果搜索的时候指定了 tags,那就应该只在包含这些 tags 的文章里查询,实现非常简单,使用 Occur::Must 即可。
fn filter_tags() {
if let Some(tags) = tags {
// 从我们先前构建的索引中取出 tags 部分的内容
let tag_facet = schema.get_field("tags")?;
let mut queries: Vec<(Occur, Box<dyn Query>)> = Vec::with_capacity(tags.len());
for tag in tags {
let facet = Facet::from(&format!("/{}", tag));
let term = Term::from_facet(tag_facet, &facet);
let tag_query = TermQuery::new(term, IndexRecordOption::Basic);
// 要求必须包含选定的 tags
queries.push((Occur::Must, Box::new(tag_query)));
}
let tag_boolean_query = BooleanQuery::from(queries);
// 与之前的查询相组合,是“与”的关系
boolean_query = BooleanQuery::from(vec![
(Occur::Must, Box::new(boolean_query) as Box<dyn Query>),
(Occur::Must, Box::new(tag_boolean_query)),
]);
}
}
生成摘要
这部分就很简单了,基本上是按照 Tantivy 的接口,把结果对应的文档路径提取出来,再生成摘要,Tantivy 生成的 snippet 有个方便的 to_html() 方法,可以直接生成 html,并在里面用 <b></b> 包住需要高亮的关键词。
fn generate_snippets() {
// 创建一个 snippet 生成器
let mut zh_snippet_gen = SnippetGenerator::create(&searcher, &boolean_query, content).unwrap();
// 设置最大的摘要长度
zh_snippet_gen.set_max_num_chars(200);
// get total matched results count
let count = searcher.search(&boolean_query, &tantivy::collector::Count)?;
let terms_iter =
top_docs
.into_iter()
.map(|(score, doc_addr)| -> Result<SearchTerm, CatError> {
let doc: TantivyDocument = searcher.doc(doc_addr)?;
let file_name = doc
.get_first(path_field)
.and_then(|v| v.as_str())
.ok_or(CatError::internal("Can not get file name"))?;
let text_zh = doc
.get_first(content)
.and_then(|v| v.as_str())
.ok_or(CatError::internal("Can not get file content"))?;
// through testing, we find that snippet is a very expensive operation
let ins = Instant::now();
let snippet_zh = zh_snippet_gen.snippet(text_zh);
log::info!("Snippet gen took: {:?}", ins.elapsed());
let fm = extract_frontmatter(file_name)?;
let res = SearchTerm {
score,
fm,
snippet: snippet_zh.to_html().trim().to_string(),
};
Ok::<SearchTerm, CatError>(res)
});
}
优化速度
目前还没有给搜索进行任何优化,我们来简单测试一下速度吧。
编译 release 版本在我的电脑上运行,搜索“rust“,搜到 4 个结果,耗时 100 多毫秒,嗯,谷歌级的速度。
仔细看看代码,发现每次搜索的时候,都会重新加载词库和索引等,使用 static 变量缓存这些内容后,程序的内存占用会从 14 m 左右来到 60 m 左右,但是搜索耗时大幅缩减,耗时 13.2 ms
还能不能再优化?经过反复测试,我发现生成摘要竟然是最耗时的操作,整个搜索耗时 13.2ms ,但生成 snippet 前只用了 916 µs,也就是说,生成 snippet 的时间占了整个搜索的时间的 93%
再仔细一看,发现每生成一个摘要,都要耗时 2-5 ms 左右,所以搜索结果越多,搜索耗时就越高。
于是我使用 rayon 库对生成摘要的过程进行了并行化,优化完后,整个搜索耗时就只有 3.5 ms 了,比之前快多了。
// DONT_FORMAT
// 使用 rayon 库并行化生成摘要的过程
let terms_iter = top_docs.into_par_iter();
当然这是在我自己电脑上的测试,实际运行这个网站的服务器 cpu 只有 2 核,所以速度要慢得多。
其他
完成上述内容后,博客的搜索系统基本就算是搭建完成了,其他的工作无非是写点 html 和 js,做个搜索页面出来。
有的人可能会问:直接用 google 搭配 site:lhz07.com 不好吗?其实我都没想到 google 爬我网站那么勤快,我既没写 robots.txt,也没写 sitemap,本来没指望 google 爬的,但是可能是因为 js 用得少吧,再加上 .com 域名,google 爬得又快又全面。
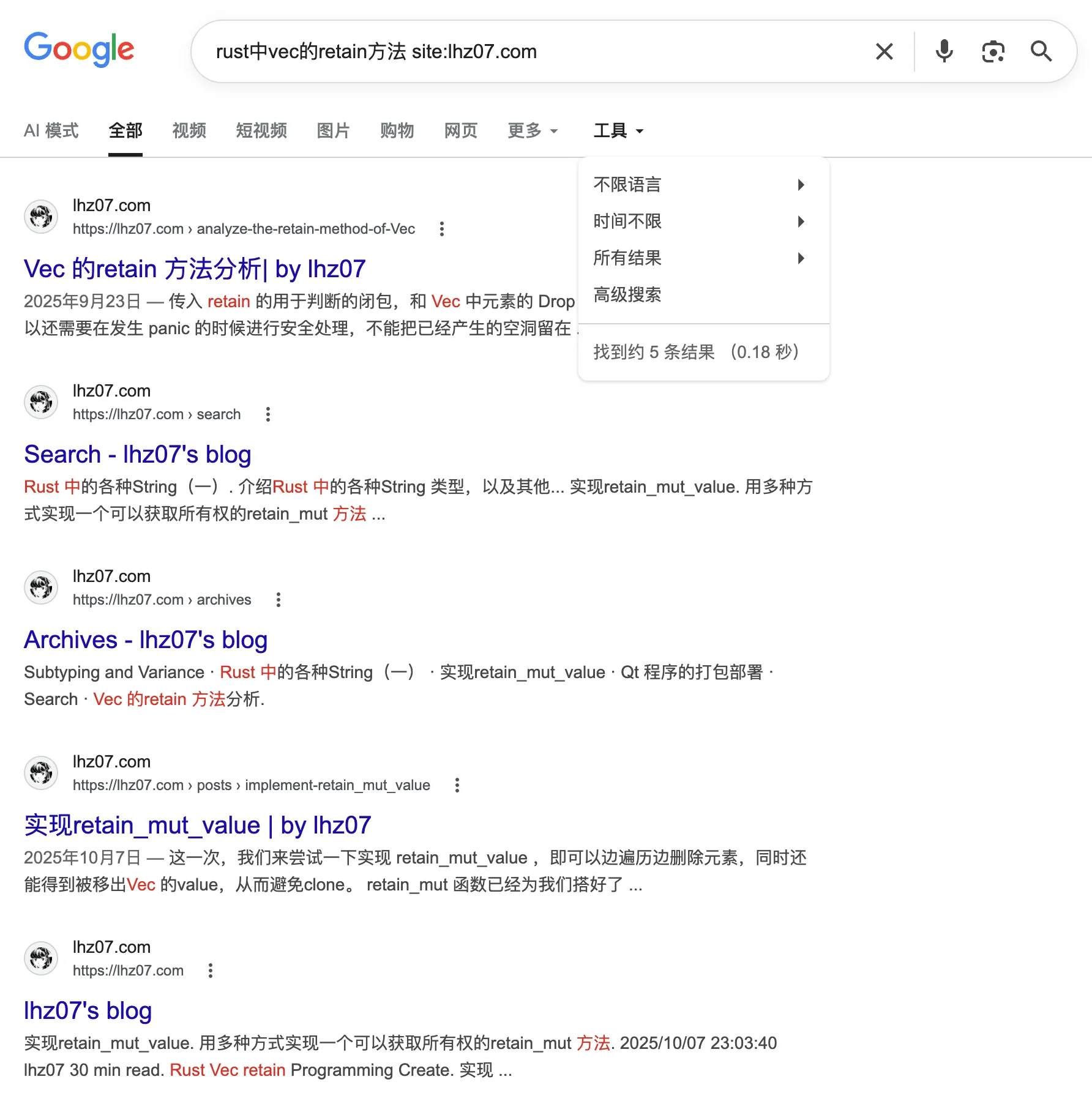
经过我的简单测试,我的搜索结果和 google 搭配 site 搜索的结果,大部分情况下基本一致,只有两点明显差别:
- 不知道为什么,google 把我的首页、搜索页和归档页都放到结果里面了,显得很乱,而且没什么用
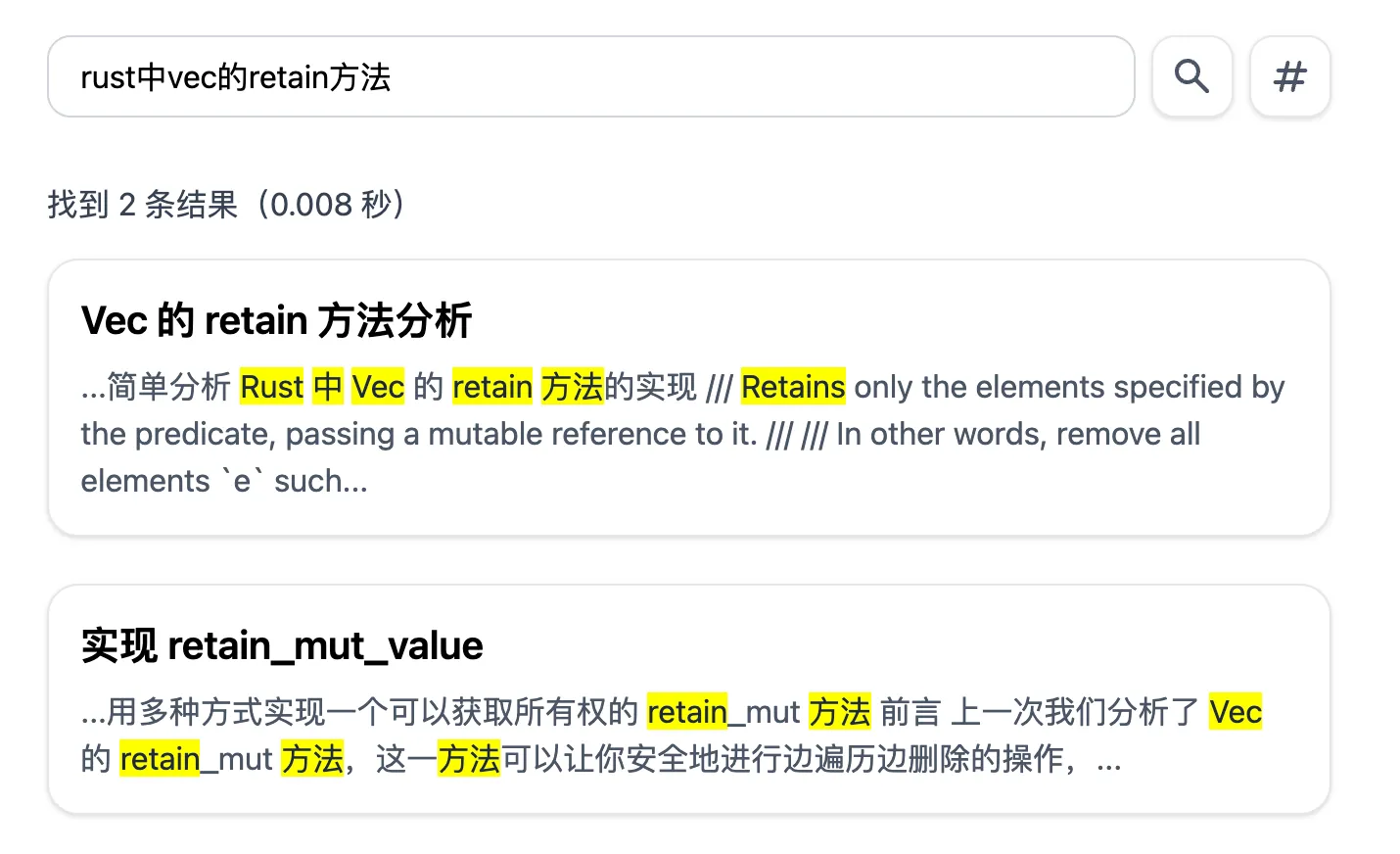
- 我的搜索更倾向于只要有任一关键词匹配,就有结果,当然,匹配所有关键词的肯定会在最前面,但是如果有只能匹配一个关键词的文章,那就也放上来,或许有用呢;但是 google 的要求所有关键词都匹配,才会有结果
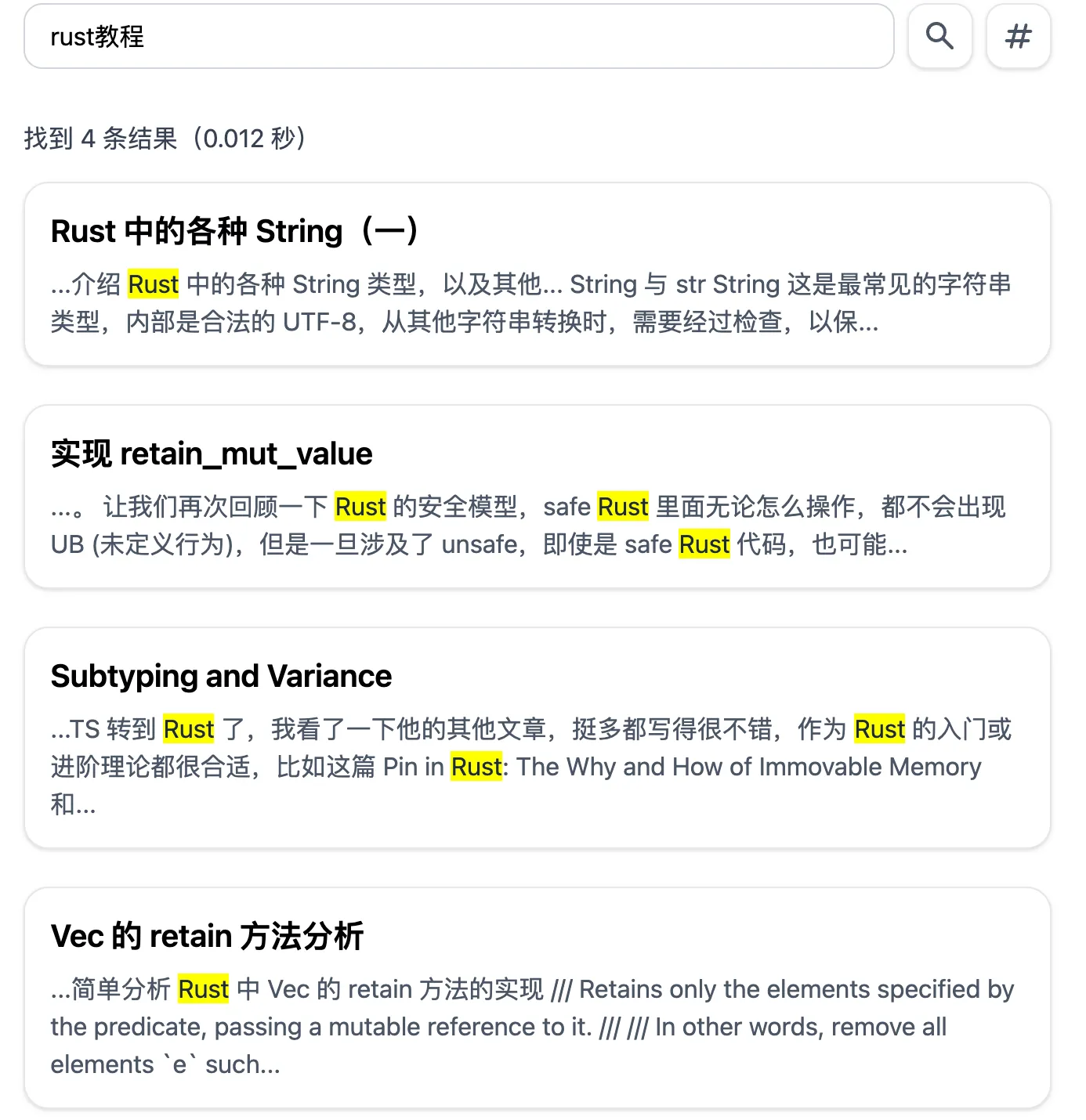
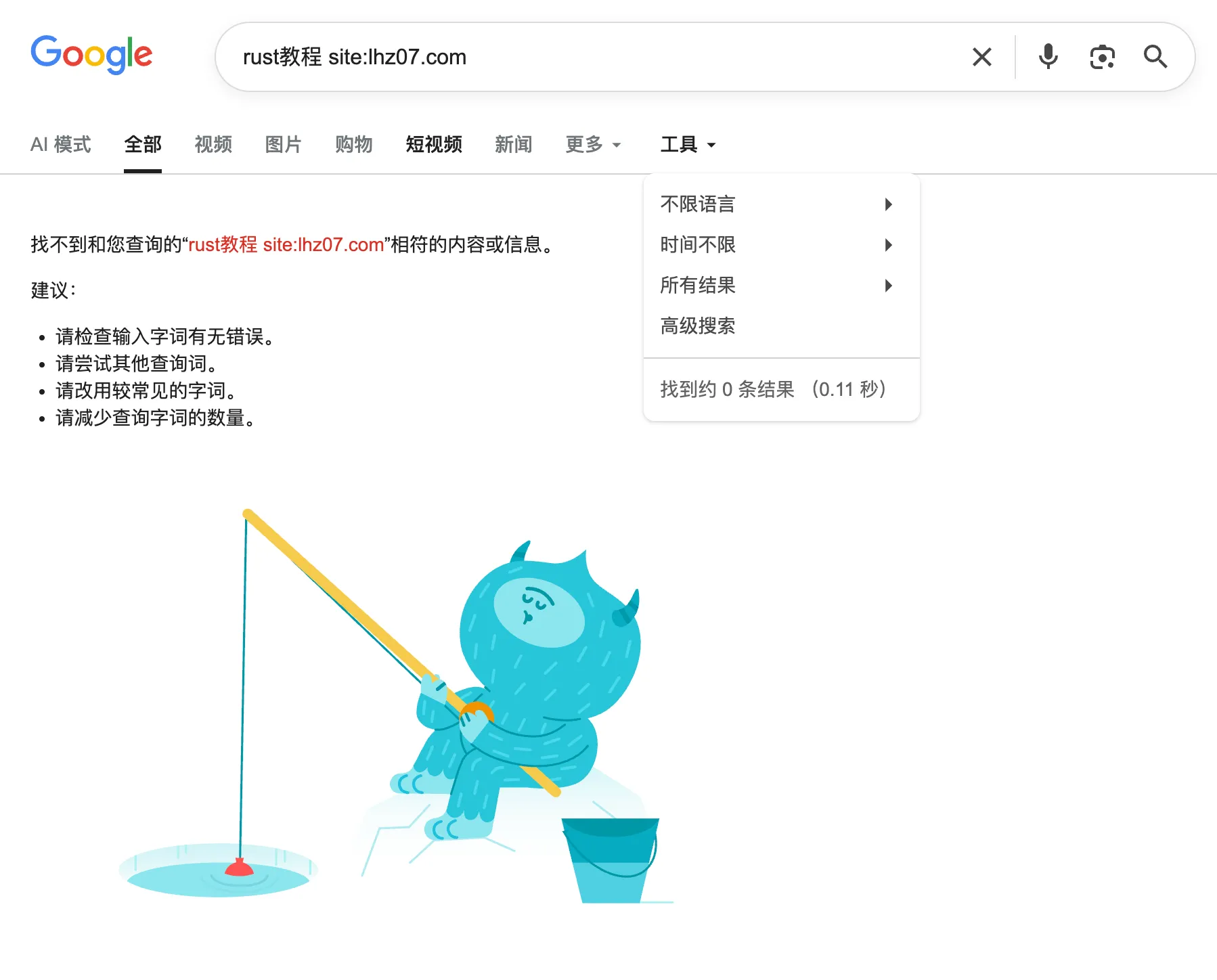
还有个好处,大概是因为我的索引小,可以全部缓存,所以速度比 google 快多了。
其实博客的搜索系统,大概在去年10月份,国庆节的时候就搭好了,一开始功能比较少,后面才加的按 tag 过滤的功能,之后想着说写一篇博客记录一下,但是也一直拖着没写,跑去写了一堆没什么用但很有意思的小项目。最近也是疏于更新,在群友的催更下,就写了这一篇。这篇文章里主要介绍了目前的搜索系统是如何实现的,至于我真正搭建搜索系统时遇到的问题,比如之前尝试过中英文分别搜索、模糊搜索之类的,就一笔带过了(主要是我也不记得了)
