写一个类似doas的程序(一)
用 Rust 写一个类似 doas 的程序,并增加更多功能
前言
在 macOS 上,我一开始用的是系统自带的 sudo,主要是方便,不用自己装。但是 Apple 似乎觉得 insults1 不文明,不符合他们高端的品牌调性,所以在编译的时候使用 --with-insults=no 选项,把我最喜欢的 insults 功能给去掉了。
为了用上 insults 功能,我只好从 sudo 的仓库自己编译,这下没问题了,用起来很舒适。但是用久了之后,我不想每次都输密码,想用 MacBook 自带的 Touch ID 来认证。如果通过 pam 来验证,系统自带的pam_tid.so 支持这个功能,但可惜的是,Apple 似乎为了安全,做了很严格的限制,只有系统自带的 sudo 能调用 pam_tid.so 进行验证,我自己编译的 sudo 用不了。
所以看起来只能 insults 和 Touch ID 二选一?我不想妥协,于是摆在面前的有两种方案:
- fork sudo 仓库,在里面调用 Objective-C 的接口,使用 LocalAuthentication 框架进行指纹认证,但后续需要跟随上游更新。
- 写一个简单的类似 sudo 的程序,可以加入 insults 功能,也可以使用 LocalAuthentication 框架进行指纹认证,后续完全自己维护。
sudo 的十几万行代码还是令我望而却步了,所以我决定自己写一个类似 sudo 的程序,然后加入一切我想要的功能。而且,我并不需要完全从头开始,应对各种意想不到的安全漏洞,我可以把 doas 移植过来,然后加点功能就行了。
说实话,我并没有兴趣,也没有精力,rewrite everything in Rust,但我还是决定用 Rust 写一个完全兼容的类似 doas 的程序,而不是在 doas 的基础上修改。原因有两点:
- opendoas 虽然可以直接在 macOS 上运行,但是不支持 timestamp 功能,也就是说,每次运行 doas 都需要输密码,即使几秒前我才运行过一次,这显然无法接受。
- 我对 C 没有那么熟悉,看看代码还行,实现几百行的 timestamp 功能,以及后期的维护,我感觉还是用 Rust 更简单。
实现
虽然 doas 非常简单,但功能也不算少,这里我们只看两个比较有意思的功能,timestamp 和配置文件解析。限于篇幅,timestamp 功能就留给下一篇吧。
解析配置文件
不同于 sudo,doas 的配置文件非常简单,每一行都是一条独立的规则,执行命令时,doas 会从上到下尝试匹配所有规则,以匹配到的最后一条规则为准,判断是否允许执行这条命令。如果你还不熟悉 doas 的规则,可以查看官方的 man page 学习一下。
在 OpenBSD 的原版 doas,和跨平台的 OpenDoas 里面,配置文件的解析都是由 parse.y2 这个文件实现的,它是 yacc 语法文件,可以使用比较简洁的语法描述解析规则,在编译的时候,会通过 yacc 自动生成对应的 C 代码,运行的时候,解析规则的就是这些自动生成的 C 代码,没有额外的依赖。
这对于 C 语言实现的 doas 来说,确实很方便,但是在 Rust 里就很麻烦了,即使在 Rust 里面通过 FFI 调用这些 C 代码,解析出来的也是 C 里的结构,Rust 代码还无法直接用。而且,对于 doas 这种配置文件,Rust 的表达力比 C 强多了。比如在 doas 里面,一条配置,解析出来的结构体是这样的:
struct rule {
int action;
int options;
const char *ident;
const char *target;
const char *cmd;
const char **cmdargs;
const char **envlist;
};
我个人感觉其实是不太完美的,做事只做了一半,比如环境变量列表,doas 的配置文件里,有多种对环境变量的操作:保留/清除某个环境变量,设置某个环境变量的值,设置某个环境变量的值为另一个环境变量。这在 C 里面表示起来并不简单,而且很容易出错,所以 doas 的做法是,直接把配置文件里的环境变量列表解析为字符串数组,之后运行时匹配规则的时候,再动态解析这些操作。
而在 Rust 里,我们可以这样表示环境变量列表:
#[derive(Debug)]
pub struct Config {
action: Action,
pub options: Options,
identity: Identity,
target: Option<String>,
cmd: Option<Cmd>,
}
#[derive(Debug)]
pub enum Env {
Keep(String),
Remove(String),
Set { key: String, val: Val },
}
#[derive(Debug)]
pub enum Val {
New(String),
FromEnv(String),
}
#[derive(Debug, Default)]
pub struct Options {
pub nopass: bool,
pub insult: bool,
pub nolog: bool,
pub persist: Option<Duration>,
pub keepenv: bool,
pub envs: Vec<Env>,
}
环境变量列表是 Options 的一部分,每个环境变量都是一个 enum,可以清晰地表达“保留/移除/设置”这三种状态。而设置环境变量,值又可以是单纯的字符串,或是来自于某个环境变量。
简单的实现
定义好了配置文件的结构,接下来就是解析配置文件,分为两步,词法分析和语法分析,语法分析听起来复杂,其实按部就班挨个解析就行,此处略过不表,我们来仔细看看词法分析。
在这里为了简单起见,我们不处理引号和转译符 (\),那么主要任务大概是这几点:
- 跳过所有空行
- 按空格分割单词
- 遇到 "#" 时,将当前行之后的内容视为注释,全部跳过
- 遇到大括号时,始终视为一个 token,即使它和后面或前面的内容间没有空格,也不受影响。
- 记录当前是配置文件的第几行,方便之后语法解析报错的时候能够带上行号。
于是我写出来了第一个版本,一次性解析完整个文件,整个文件是一个数组,数组的每个元素也是一个数组,代表着一条配置,里面有多个 Tokens
我上个月给网站加入了在线运行 Rust 代码的功能,点击代码块右上角的运行按钮试试吧!
// runnable
use std::mem;
// ANCHOR
const CONTENT: &str = r#"# set nopass for tedu
permit nopass keepenv tedu as root cmd /usr/sbin/procmap
permit persist lhz# set persist
permit persist setenv {PKG_CACHE PKG_PATH } aja cmd pkg_add"#;
// 这里每个 Token 都记录着自己的行号,因为之后加上转译符后,一条配置可以跨越多行,所以即使在同一条配置里,
// 每个 Token 的物理行号都可能是不同的。
#[derive(Debug)]
pub struct Token(String, usize);
fn tokenizer(content: &str) -> Vec<Vec<Token>> {
// 暂时存放当前 token
let mut token = String::new();
// 暂时存放当前行
let mut tokens = Vec::new();
// 最终的结果数组
let mut lines = Vec::new();
let mut skipping_comment = false;
let mut line_count = 1;
for ch in content.chars() {
// 跳过后面的所有内容,直到下一行
if skipping_comment {
if ch != '\n' {
continue;
} else {
// ch == '\n'
skipping_comment = false;
}
}
match ch {
'\n' => {
// 遇到了换行符,表示下面就是新的一行了。
// 比如最简单的规则,permit alice
// 如果 alice 的后面还有个空格,那这个 token 应该已经被推进去了,当前 token 是空的,则什么都不做。
// 否则,上一个字符应该是 'e',当前的 Token 是“alice”,此时 '\n' 起到了分隔的作用,
// 我们需要把当前的 token 推到当前行的末尾。
if !token.is_empty() {
tokens.push(Token(mem::take(&mut token), line_count));
}
// 如果当前行已经有内容了,那就推入 lines。
if !tokens.is_empty() {
lines.push(mem::take(&mut tokens));
}
// 因为遇到了换行符,所以物理行数加一
line_count += 1;
}
_ if ch.is_ascii_whitespace() => {
// 遇到了空格,如果当前的 token 不为空,那就推到 tokens 里去。
if !token.is_empty() {
tokens.push(Token(mem::take(&mut token), line_count));
}
continue;
}
'{' | '}' => {
// 遇到了大括号,大括号应该视为单独的 token,所以如果当前已经有 token 了,那就把它交给 tokens
if !token.is_empty() {
tokens.push(Token(mem::take(&mut token), line_count));
}
// 把大括号本身也作为一个单独的 token 放进 tokens 里面
token.push(ch);
tokens.push(Token(mem::take(&mut token), line_count));
continue;
}
// skip comment
'#' => {
// 注释从这里开始,即使当前的 token 或 tokens 不为空,也没关系,它们要么会在遇到下一个换行符的时候被处理,
// 要么这是个不规范的文件,最后一行没有以换行符结尾,这也没关系,我们在遍历完所有字符之后,会额外检查一次当前是否
// 有未处理的 token 或 tokens
skipping_comment = true;
}
_ => {
token.push(ch);
}
}
}
// 最后额外检查当前是否有未处理的 token 或 tokens,避免漏掉规则
if !token.is_empty() {
tokens.push(Token(mem::take(&mut token), line_count));
}
if !tokens.is_empty() {
lines.push(mem::take(&mut tokens));
}
lines
}
fn main() {
let tokens = tokenizer(CONTENT);
for token in tokens {
println!("{:?}", token);
}
}
// ANCHOR_END
目前来看,这个实现很不错,至少按照 man page 的定义来说,应该能解析任何不带引号和转译符的 doas 配置文件了。但是从效率上来看,能不能更高效一点呢?目前需要一个大的数组来存储这些 tokens ,能不能做成流式解析,把内存空间压缩到单个 token 呢?
流式解析器
当然可以,使用生成器3就可以做到这一点。
于是可以得到第二个版本,和第一个版本的差别很小。主要差别就两点:
- 推入
Vec的操作变成了yield,为了区分是当前这条规则的 token,还是要换到下一条,我加入了State,每次切换到下一条规则的时候,就返回一次NewLine,表示当前规则结束了。 - 虽然我们不再使用
Vec了,但仍然需要记录当前这一行是否有内容,这样才能决定是否要返回NewLine表示当前这条规则结束。空白行或者注释行应该直接跳过,不应该返回NewLine。所以使用token_empty变量来记录当前行是否有内容,它的作用相当于之前的tokens.is_empty()
但是从性能上来说,差距就大多了,这个版本完全不需要额外的数组空间,编译器会把它编译成无栈协程,开销就跟手写迭代器差不多,甚至由于是编译器自己生成的状态机,优化更好,可能速度更快。
// runnable nightly
#![feature(gen_blocks)]
use std::mem;
const CONTENT: &str = r#"# set nopass for tedu
permit nopass keepenv tedu as root cmd /usr/sbin/procmap
permit persist lhz# set persist
permit persist setenv {PKG_CACHE PKG_PATH } aja cmd pkg_add"#;
// ANCHOR
#[derive(Debug)]
pub enum State {
Token(String, usize),
NewLine(usize),
}
gen fn tokenizer(content: &str) -> State {
let mut token = String::new();
let mut skipping_comment = false;
let mut token_empty = true;
let mut line_count = 1;
for ch in content.chars() {
if skipping_comment {
if ch != '\n' {
continue;
} else {
// ch == '\n'
skipping_comment = false;
}
}
match ch {
'\n' => {
if !token.is_empty() {
token_empty = false;
yield State::Token(mem::take(&mut token), line_count);
}
if !token_empty {
token_empty = true;
yield State::NewLine(line_count);
}
line_count += 1;
}
_ if ch.is_ascii_whitespace() => {
if !token.is_empty() {
token_empty = false;
yield State::Token(mem::take(&mut token), line_count);
}
continue;
}
'{' | '}' => {
if !token.is_empty() {
token_empty = false;
yield State::Token(mem::take(&mut token), line_count);
}
token.push(ch);
yield State::Token(mem::take(&mut token), line_count);
continue;
}
// skip comment
'#' => {
skipping_comment = true;
}
_ => {
token.push(ch);
}
}
}
if !token.is_empty() {
token_empty = false;
yield State::Token(mem::take(&mut token), line_count);
}
if !token_empty {
yield State::NewLine(line_count);
}
}
// ANCHOR_END
fn main() {
let tokens = tokenizer(CONTENT);
for token in tokens {
println!("{:?}", token);
}
}
但是 gen blocks 目前仍然是 Rust 的不稳定特性,能不能在 stable 版本下实现类似的功能呢?
手写生成器
完全可以,因为我们的逻辑比较简单,只需要实现一个简单的状态机就行了。
// runnable
use std::mem;
use std::str::Chars;
const CONTENT: &str = r#"# set nopass for tedu
permit nopass keepenv tedu as root cmd /usr/sbin/procmap
permit persist lhz# set persist
permit persist setenv {PKG_CACHE PKG_PATH } aja cmd pkg_add"#;
#[derive(Debug)]
pub enum State {
Token(String, usize),
NewLine(usize),
}
// ANCHOR
pub struct Tokenizer<'a> {
content: Chars<'a>,
token: String,
skipping_comment: bool,
token_empty: bool,
line_count: usize,
location: Option<Location>,
}
enum Location {
TokenEmptyLineCount,
LineCount,
ReturnBrace(u8),
}
impl Iterator for Tokenizer<'_> {
type Item = State;
fn next(&mut self) -> Option<Self::Item> {
self.next_impl()
}
}
impl<'a> Tokenizer<'a> {
pub fn new(content: &'a str) -> Self {
Self {
content: content.chars(),
token: String::new(),
skipping_comment: false,
token_empty: true,
line_count: 1,
location: None,
}
}
fn next_impl(&mut self) -> Option<State> {
// 如果上次调用的时候,记录了这次要做什么,那就先把要做的事做了,之后再进入循环。
if let Some(location) = self.location.take() {
match location {
Location::TokenEmptyLineCount => {
if !self.token_empty {
self.token_empty = true;
self.location = Some(Location::LineCount);
return Some(State::NewLine(self.line_count));
}
}
Location::LineCount => self.line_count += 1,
Location::ReturnBrace(ch) => {
self.token.push(ch as char);
return Some(State::Token(mem::take(&mut self.token), self.line_count));
}
}
}
for ch in &mut self.content {
if self.skipping_comment {
if ch != '\n' {
continue;
} else {
// ch == '\n'
self.skipping_comment = false;
}
}
match ch {
'\n' => {
if !self.token.is_empty() {
self.token_empty = false;
// 如果这是在 C 里面,也许可以记录下标签,下次直接 goto 到特定位置。但这是 Rust,只能记录下次要做什么
self.location = Some(Location::TokenEmptyLineCount);
return Some(State::Token(mem::take(&mut self.token), self.line_count));
}
if !self.token_empty {
self.token_empty = true;
// 其实这里也可以不要 `LineCount` 分支的,先加一,再返回旧的值就行了。但是这么实现的好处是,返回之后,状态是一致的,
// 既可以使用返回的 line_count,也可以直接从结构体取 line_count,值都是一样的。
self.location = Some(Location::LineCount);
return Some(State::NewLine(self.line_count));
}
self.line_count += 1;
}
_ if ch.is_ascii_whitespace() => {
if !self.token.is_empty() {
self.token_empty = false;
self.location = None;
return Some(State::Token(mem::take(&mut self.token), self.line_count));
}
continue;
}
'{' | '}' => {
if !self.token.is_empty() {
self.token_empty = false;
self.location = Some(Location::ReturnBrace(ch as u8));
return Some(State::Token(mem::take(&mut self.token), self.line_count));
}
self.token.push(ch);
return Some(State::Token(mem::take(&mut self.token), self.line_count));
}
// skip comment
'#' => {
self.skipping_comment = true;
}
_ => {
self.token.push(ch);
}
}
}
if !self.token.is_empty() {
self.token_empty = false;
self.location = Some(Location::TokenEmptyLineCount);
return Some(State::Token(mem::take(&mut self.token), self.line_count));
}
if !self.token_empty {
self.token_empty = true;
// 如果代码运行到这里,证明最后一行缺少换行符,这已经是最后一行了,所以之后不需要再增加计数,也就不需要设置 location
return Some(State::NewLine(self.line_count));
}
None
}
}
// ANCHOR_END
fn main() {
let tokenizer = Tokenizer::new(CONTENT);
for token in tokenizer {
println!("{:?}", token);
}
}
状态机示意图
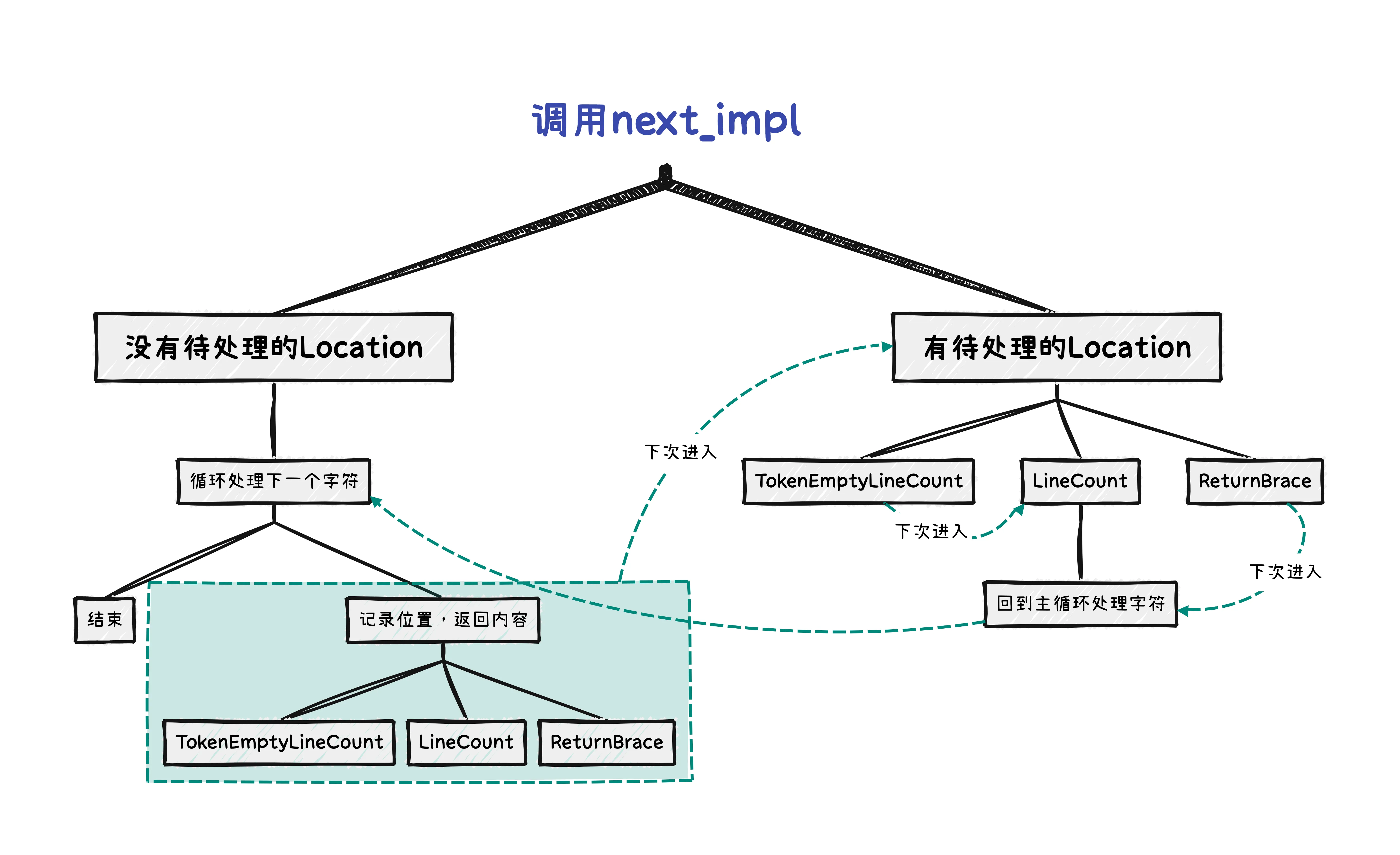
最后
以上就是本篇文章的全部内容了,用三种方式实现了完全相同的词法解析器,感觉还是挺有意思的。
虽然这系列的文章还没有写完,但我的 doas 已经写好了,并且已经使用了一段时间,可以去我的 GitHub 仓库 看看。目前还是 macOS only 的,因为我做它的初衷就是想在 macOS 上同时用上 insults 和 Touch ID,如果是在 Linux 上的话,已经有 sudo, sudo-rs, opendoas 可以用了,选择很多。

